Increasing Mini-Batch Size While Preserving Accuracy for Distributed Deep Learning
Event Type
ACM Student Research Competition: Graduate Poster
ACM Student Research Competition: Undergraduate Poster
Posters
In-Person Only
TP
XO / EX
TimeTuesday, 16 November 20218:30am - 5pm CST
LocationSecond Floor Atrium
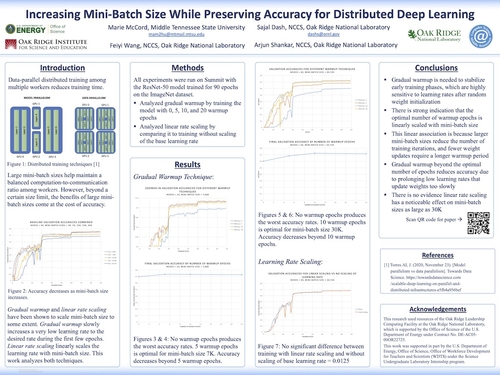
DescriptionData-parallel distributed training is an effective way to reduce training times for complex deep learning models and large-scale datasets. In distributed training, each worker requires enough work to justify the communication overhead and maintain a balanced computation-to-communication ratio. This issue can be addressed by using large mini-batch sizes, which refer to the size of the chunk of training data that is processed through the network during a single training iteration. However, beyond a certain size limit, the benefits of large mini-batch sizes come at the cost of accuracy. This research focuses on understanding the effects of large mini-batch sizes on accuracy and the underlying training dynamics. The techniques of gradual warmup and linear scaling of the learning rate were analyzed. There is evidence that the optimal number of warmup epochs is linearly associated with mini-batch size, and linear scaling does not appear to impact mini-batch sizes as large as 30K.
Archive view
